
Python Recommendation Engines with Collaborative Filtering
Recommendation systems are one of the most powerful types of machine learning models.
Within recommendation systems, collaborative filtering is used to give better recommendations as more and more user information is collected. Collaborative filtering is used by large companies like Netflix to improve the performance of their recommendation systems.
This shows that recommendation systems that use collaborative filtering are powerful. This tutorial will teach you how to build Python recommendation engines with collaborative filtering.
Table of Contents
You can skip to a specific section of this Python recommendation engine tutorial using the table of contents below:
Introduction
Recommendation engines is the umbrella term for the type of information filtering engine that aims to make predictions on consumer ratings as well as preferences on physical and virtual items. Although their core application lies in the commercial sector, these recommendation engines can be seen across many more disciplines as well. There are many algorithms and techniques to develop these recommendation systems. However, amongst them all, collaborative filtering is one of the most widely used techniques in the development of recommendation engines that are not only effective but also very versatile depending on the target application.
The core idea of collaborative filtering is that it sweeps through a large set of users with a range of different tastes on the items of consideration. Among these users, the intended collaborative filtering algorithm then finds niche groups of people that are alike or relatable in different ways and composes the items after the rankings of each group.
In collaborative filtering, it is usually up to the developer to come up with the algorithm to make predictions, and hence, there is more than one way to find new users that align with these niches. In this tutorial, we will get an idea about how to perform collaborative filtering using Python.
Before starting with any coding, we will take a look at some of the applications of collaborative filtering. Afterward, we will acquire some prerequisite knowledge that is essential in getting a good foundation for the topic we will be covering today. Finally, we will build a simple recommender system using Python and a few libraries.
Let’s get started.
Applications and Challenges of Collaborative Filtering
We now vaguely know what collaborative filtering is about and how it can be used to identify the relationships users have with different items. Before we dive into the theories, it is helpful to set the background if we have an idea about why we do what we do. Therefore, we will now look at a few instances where we can use collaborative filtering as a recommender engine technique.
When it comes to building recommendation engines, collaborative filtering does not necessarily require any data or information about the features of the users available beforehand. This is a really good plus point when we are subjecting items from a general space such as a supermarket. Although we can take hybrid approaches with having a bit of an idea about the features of the items of consideration, collaborative filtering eliminates that need and still allows the development of a decent recommendation engine.
Moreover, collaborative filtering refrains from the overspecialization of users or items as it is only interested in the relationship the users have with the items. For instance, if your store sells watches, you might want to use collaborative filtering if you do not want the recommendation engine to suggest similar types of watches to a consumer who just purchased a watch.
In collaborative filtering, there are also a few inherent shortcomings one should be aware of if they are integrating this in their recommender. For instance, there could be long periods of elusiveness for newly added items as it takes time for users to rate and build a relationship with them. Moreover, items that have not been purchased or rated might never pop up in the recommendation engine if collaborative filtering is used.
Prerequisite Concepts
Collaborative filtering is not just one entity that can be learned in one go. There are a few core ideas that might be useful in knowing if you are to apply this technique in your application. Although we might not be using some of these concepts in our codes today, it is still essential that you are knowledgeable about it. Some of these concepts might be very new to you and therefore, might sound very difficult. However, it should be understood that once you get the grasp of the core idea, it is nothing more than another tool to make our algorithms much more effective and optimized. Let’s get started.
1. Dimensionality Reduction
Let’s consider an application where we build a recommendation engine for a bookstore. We have been collecting user ratings on different books for a while, and let’s say that we have 500 users having rated 5000 books. This does not mean that all the users have ratings for all the books. Sometimes, there could be users that have not rated any book and there could also be books with no ratings from anyone. However, provided this information, we can come up with a 500x5000 user-book matrix. Since we already know that this matrix has lots of empty cells, we can use dimensionality reduction to improve the algorithm both memory and time-wise.
In other words, with dimension reduction, we can transform data from a higher number of dimensions to a lower number of dimensions while retaining meaningful information about the original data. There are many techniques to achieve this such as principal component analysis, generalized discriminant analysis, linear discriminant analysis. Although we will not be going through all of these, PCA would be a good starting point.
2. Principal Component Analysis
Consider an instance where we are given 100 vehicles and we are asked to determine which ones are functional and which ones are ready to be shredded. We know that vehicles have various features such as the number of tires, manufactures year, color, engine capacity, mileage, etc. Among these features, we do realize that some of the aesthetic features might not be very useful in determining the answer to our question. In simple terms, we can use PCA to identify the features of a dataset that can be easily eliminated without losing many features of the original number of dimensions.
3. K-Nearest Neighbours
The K-Nearest neighbors is one of the simplest statistical learning algorithms that can be used to classify information. It mainly started with the assumption that similar things always reside close by to each other.
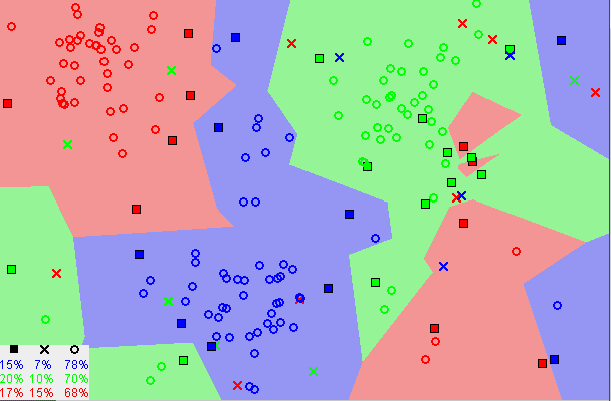
Agor153 / CC BY-SA (https://creativecommons.org/licenses/by-sa/3.0)
For instance, consider the above figure. If we look at it, we can see that there are different types of shapes and symbols. Naturally, similar ones are residing close to each other. However, consider that we place a new symbol on the above space and we are required to determine the nature of it. In such an event, we can use the KNN algorithm to find out the group in which this new member belongs to. In KNN, K is an integer parameter that we have to usually find by trial and error. It denotes the K number of closest neighbors to a specific point of interest in the above space.
We have now covered a few core concepts that will be useful for us when we are dealing with collaborative filtering. Let’s move on to the most awaited section of today’s tutorial, the implementation.
Let’s Build a Recommender Using Python
We are now ready with the theories and the background knowledge we require to develop a recommendation engine using collaborative filtering. However, we still need to set up the programming environment. Therefore, let’s go ahead and install NumPy, Pandas, and the Surprise library from SciKit.
pip install numpy
pip install pandas
pip install scikit-surprise
Before we start coding, let’s get to know one last thing. The Surprise library is also equipped with many built-in datasets and functions that are highly useful when we are dealing with data. Without using external libraries or functions, we can easily import these datasets into our code for experimentation purposes easily. Let’s load the MovieLens dataset now.
from surprise import Dataset as ds
dataset = ds.load_builtin('ml-100k')If we look at the nature of this dataset we just loaded, it will be as follows.
<surprise.dataset.DatasetAutoFolds at 0x7f20b8ccf160>
If we are to load a pandas dataframe as a Surprise dataset object, we can also easily perform it as follows. Imagine we have a pandas dataframe called df.
dataset = ds.load_from_df(df, Reader(rating_scale=(1, 5)))In the above, we are passing a Reader object as the 2nd parameter to the loadfromdf method. Reader class is used to create file parsing objects that have user ratings. For instance, in our example, we are using a 1 to 5 rating scale. There are also other parameters in Reader objects such as lineformat, skiplines, and sep.
If we are to convert a Python dictionary to a Surprise dataset object, we can easily convert it to a dataframe object of Pandas and then convert it to a dataset object using loadfromdf function.
Now that we are well versed in the background, let’s go ahead with our recommendation engine.
1. Building a Model
As it has been specified before, it is the developer's decision to pick the algorithm for their recommendation engine. For this example, we will choose the K-Nearest Neighbors statistical learning algorithm as our approach. Thankfully, it is also available in the Surprise library under the name KNNWithMeans. We will also specify the keys that are required for the dictionary that will be used in our algorithm.
from surprise import KNNWithMeans as centeredknn
sim_options = {
"name": "cosine",
"user_based": False
}
model = centeredknn(sim_options=sim_options)If the above snippet is considered, we can see that we are configuring it with the name cosine and the userbased key as false. There is also another parameter called minsupport that will configure the threshold minimum for the mutually rated items among users. The first key ‘name’ takes in other values such as msd, pearson, and another value called pearson_baseline. The 2nd key specifies if the subject of consideration is the user or the item.
We can now go ahead with the rest of our code. Let’s use another in-built function and build the trainset. It should be noted that this trainset contains meta-information about the available set of data. This is also the point where we divide the dataset to training and testing data. It should also be noted that if we are using a sufficiently large dataset, we can also do K-fold cross-validation.
movie_data = Dataset.load_builtin('ml-100k')
training_set = movie_data.build_full_trainset()We have now imported the movie data from earlier. Let’s finally fit our model and then make a prediction for the rating from a user ‘101 for the movie ‘1051’.
model.fit(training_set)
model.predict('101', '1051')This would output
Prediction(uid='101', iid='1051', r_ui=None, est=2.9069991028991753, details={'actual_k': 40, 'was_impossible': False})
If we look at the est value, it would approximately say 2.9070. This means, the user 101 has given a rating of 2.9070 for the movie 1051.
If we put together the whole code, it would be as follows.
from surprise import KNNWithMeans as centeredknn
sim_options = {
"name": "cosine",
"user_based": False
}
model = centeredknn( sim_options = sim_options )
movie_data = Dataset.load_builtin('ml-100k')
training_set = movie_data.build_full_trainset()
model.fit(trainingSet)
model.predict('101', '1051')We can create another model using singular value decomposition. This has also been provided by the Surprise module.
from surprise import Dataset
from surprise import SVD
model = SVD()
movie_data = Dataset.load_builtin('ml-100k')
training_set = movie_data.build_full_trainset()
model.fit(training_set)
model.predict('101', '1051')If we make the same prediction we did earlier about the rating from the user ‘101’ about the movie ‘1051’, it would return a value of 2.807. Although the values are not exact in these two models, they are approximately close. Therefore, we can believe that both the models are functioning the same way.
Feel free to go ahead and try out other available models and configurations. It might take a while, but it is definitely well worth the effort if your long term goal is to become an expert in this realm.
We will now take a look at how parameter tuning can be performed with these collaborative filtering models.
2. Tuning a Model
The Surprise library is a complete library that it has provided us with tools related to parameter tuning as well. For instance, we have been provided with a GridSearchCV class that can be used for tuning your model.
from surprise import Dataset as ds
from surprise import KNNWithMeans as centeredknn
from surprise.model_selection import GridSearchCV as gs
movie_data = ds.load_builtin('ml-100k')
training_set = movie_data.build_full_trainset()We will start with importing the required libraries and then importing the dataset.
Then we will configure the sim options.
sim_options = {
"name": ["msd", "cosine"],
"min_support": [3, 4, 5],
"user_based": [False, True],
}Then we will build a grid search model and find the root mean square error as follows.
grid_search = gs(centeredknn, confs, measures=["rmse", "mae"], cv=3)
grid_search.fit(movie_data)
print(grid_search.best_score["rmse"])This would output
0.9432873118734979
Moreover, if we check print(gridsearch.bestparams["rmse"]), it would inform us that the best params resulted from the ‘msd’ model. Therefore, we can come to the conclusion that for the dataset we chose, the K-Nearest Neighbors algorithm performs best when we go with the msd settings and cv = 3 settings.
Final Thoughts
Collaborative filtering is one of the many ways that you can build recommendation engines. We learned quite a bit about the background and the prerequisite knowledge that is essential if one is aspiring to become specialized in this field. We later built and tuned a recommendation engine using the Surprise library.
There are so many instances where collaborative filtering is the ideal option, although it is not always the most optimal approach to take. It all depends on the application, and it is generally best to follow a hybrid approach which might be based on collaborative filtering.